Execution Engine
Most of this information is several years old, however most of the fundamental concepts are still valid.
Current System
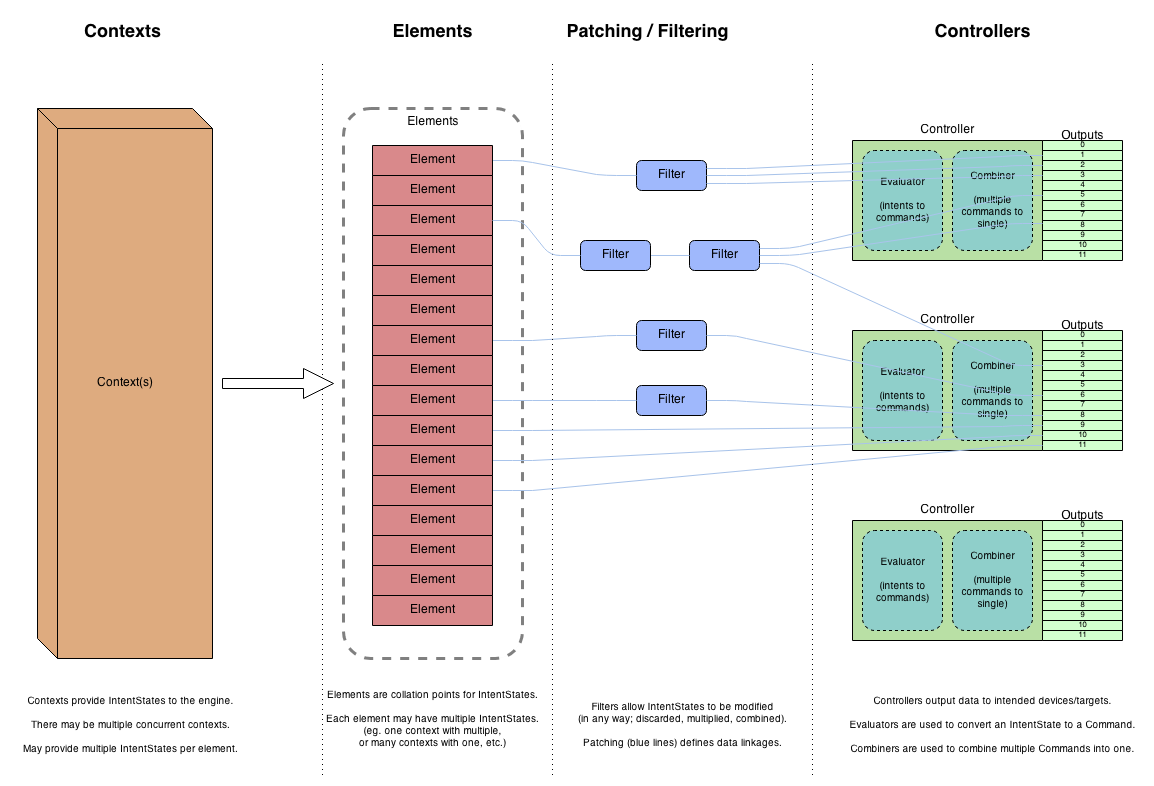
The goal of the execution engine is to take data from any number of currently running sources (Contexts), and end up with a single value for each output on each controller. It does this in a number of different stages.
The input data to the execution engine (from contexts) is an abstract data type (Intents), which represents the intended result for the element it targets. For example, it might specify to turn a light on to 50% brightness and color red. It does not specify any particular limitation or method on how that result should be implemented; that is the responsibility of the execution engine.
The end result of the execution engine is a data type called Commands. These are low-level data types which are in formats suitable for that specific controller. For example, it might be an 8-bit numeric value for one controller type, or a 16-bit numeric value for another.
In the diagram above, moving from left to right you can see the data flow process. The goal is to reduce many Intent data objects (on the left) to a single Command object (on the right), one per channel.
Contexts
The contexts are the sources of any data into the engine. Presently, there are two context types; a Sequence Context, and a Live Context. Both are currently used.
Sequence Context
A sequence context provides intents during execution of a sequence. Each effect is rendered to a collection of intents targeted on elements. During execution, the context provides these intents to the execution engine at the appropriate time (ie. while the effect is active).
Live Context
The live context is currently used for the effect preview in the sequencer and the web interface. The idea is to have a context that can be used for immediate execution of single effects. This could be used for testing/setup purposes, or for things like responsive displays (eg. triggering on user input, etc.)
Elements
The elements represent the abstracted items in the display. These would be things like Megatree strand, Minitree, etc. They should have no bearing whatsoever to the controllers and outputs used to implement a display. Because of this, elements utilize Intents to describe the activity currently taking place.
When the execution engine updates, it collects all intents for each element. Each element can contain zero or more current intents.
Patching & Filtering
To connect the intents on each element to the outputs on controllers, the data is patched. This connects the output of one block with the input of another. However, there is also some conversions that need to take place. There needs to be some intelligence or process that the user can utilize to describe how element intent data should end up as controller command data, as there may need to be some data conversion performed. These can be implemented as Filters.
Filters can be added in the data path between elements and controllers to help describe the process to take to accurately convert intended effects to real commands for controllers. For example, it is common for displays to implement multi-colored lighting elements with individual colors on each controller output (eg. an RGB item might use 3 channels: one for each color). To connect that RGB item to the appropriate channel, a Color Breakdown filter could be used. This would have one input (from the element), and be configured to have 3 outputs (one for each channel). The filter would process the incoming data, and split out the color portions of each lighting intent, into individual intents (one per color).
Additionally, to get from intent data on each element to the final command on each output, two things need to happen:
- The Intent data types need to be converted to a Command data type. This is called Evaluation.
- If there is multiple data objects destined for a single output, they need to be reduced to just one. This is called Combination.
For example, a lighting intent of turn on element to 50% brightness, color red might end up as a command on a red output channel with an 8-bit value of 128. The user can utilize filters to implement these steps if they want.
However, it is not strictly required: it is possible to patch elements directly to controller outputs (or through minimal filters that do not perform the two conversions). This is because each controller must provide a default or fallback way to perform these conversions.
Controllers
The controller framework takes the data processed by the rest of the system, and ultimately provides it to the specific controller module implementation, to actually output the data. However, there is also some extra things the controllers need to do.
A controller must specify a default Evaluator and Combiner that it wants to use to process the data, if it has input data which is not in the appropriate format. This allows a minimal set of patching; with sensible defaults, many controller modules can take data directly from elements, and convert them themselves.
Any input intent data is passed through the specified Evaluator. This will convert the data to a command. For example, the above mentioned lighting intent (brightness at 50%) might be converted to an 8-bit value of 128 for many controllers. (The color component of the intent could reasonably be ignored, as there is no way for the controller to make an informed decision as to what to do with it.) Note that this is a direct 1:1 correlation: no combining is performed at this step.
Once all intents have been converted to commands, the controller can combine them to a single command. (This is because channels need a single concise command value to output.) This Combiner should take multiple commands, and give a result of a single command.
A number of problems became apparent with the way this system operates during 2013, which required improvements/refinements to the operation of the engine.
Problems & Causes
Memory Usage
Users have reported extremely high memory usage when using V3 for their displays in 2013 in the order of multiple gigabytes. This is caused by a number of things:
- When pre-rendering effects, the effect renders and stores the intent data. Intents have a small amount of overhead. Normally this isn’t an issue, as intents were conceived to represent a range of raw values (ie. a single intent might represent 20 or 50 raw values in one object). Often, an intent can be smaller in memory than the equivalent raw values it renders to. However, when using Nutcracker effects, or when importing V2 sequences (with many tiny effects), a lot of redundant data objects (and overhead) are generated.
- When using the scheduler to run a show, the scheduler loads ALL sequences used into memory, and pre-renders them all. If using a lot of sequences, this can often blow out memory usage.
- Some of the data formats used waste memory. For example, using doubles to store color parameters instead of floats.
CPU Load
Users have also reported unreasonably high CPU load when running sequences. This is due to many factors, some small and some large. However, the primary one (relevant to this discussion) is the processing of intents in the execution engine, in real-time. That is, the:
- Instantaneous sampling of the current Intent objects in contexts to get IntentStates,
- Any filtering performed in the filtering and patching steps (eg. color breakdown filters, dimming filters),
- The evaluation of the IntentState object to get a specific Command, and
- Other miscellaneous overhead during the process (patching, object creation and disposal through the layers, etc.)
Scheduler Problems
Users have reported problems with the scheduler when executing shows. Some are caused by the memory usage (described above), however another common issue is that shows do not start on time (eg. 15 minutes after the scheduled start). This is caused by the operation of the scheduler: at the start time, it loads and renders all sequences that will be used. If there are complex sequences, or lots of them, this can take a significant amount of time, delaying the start of the show.
This problem, while valid, is not strictly related to the current topic of the execution engine. Some of the problem should be fixed within the scheduler operation (for example, loading sequences ahead of time, instead of doing preparation at the start of the show). However, the changes and solutions discussed below will significantly help fix this issue.
Proposed Solution
To solve the above problems, a number of changes can be made to the operation of the execution engine. The main problems above relate to CPU and memory usage. To solve these, we can doing the intensive work ahead of time (saving CPU load), and reduce the amount of data we actively hang on to in memory (reducing memory usage).
The following solution has come about as a combination of a lot of the ideas that dev group members have been discussing and suggesting over the last few months.
To explain the solution, first consider a more detailed view of how contexts operate:
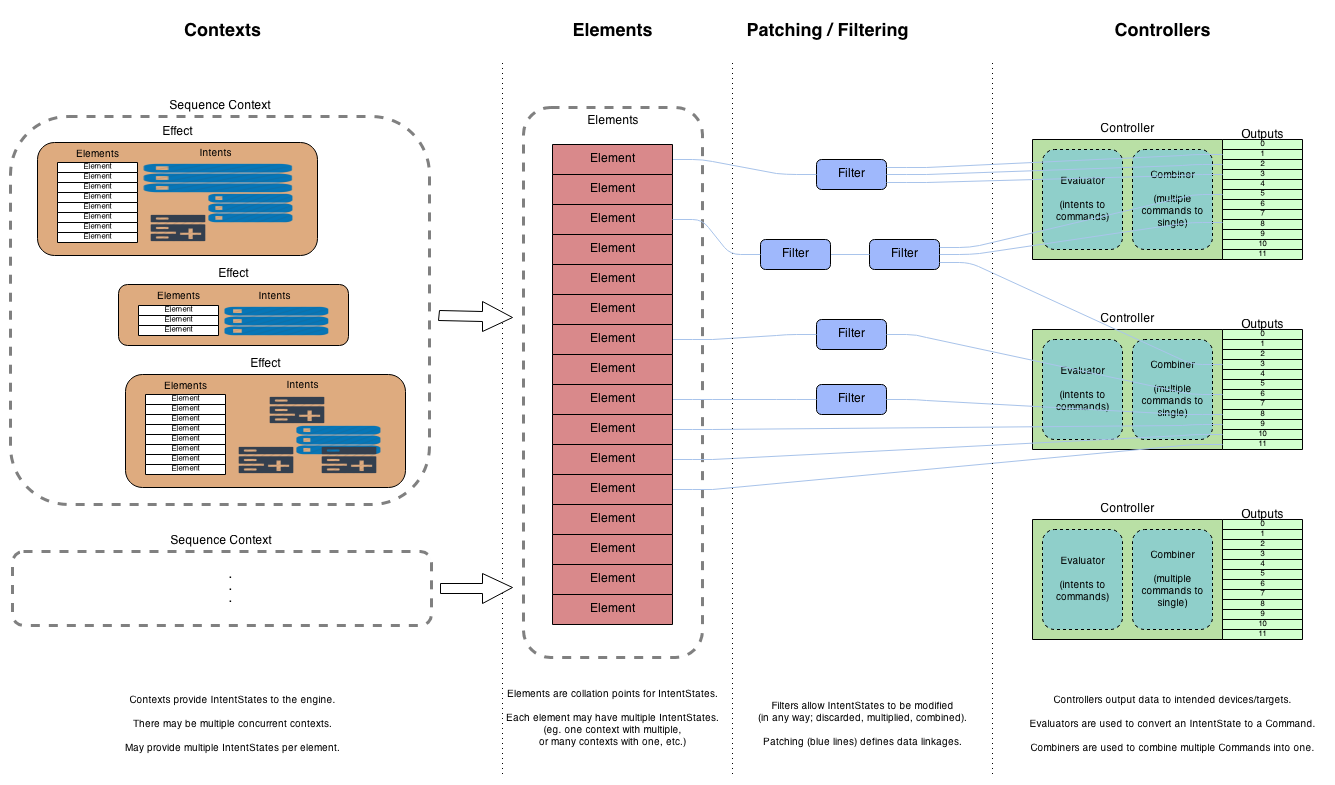
Note that there can be multiple contexts active at any time, even though the diagram only shows one main one. For example, we might have multiple sequences playing, or a sequence playing with some live data added, etc.
Currently, a sequence context contains effects, which all have been rendered against their target elements (usually ahead of time). These effects have collections of Intents to apply to elements at the appropriate time when the system is updated. When that happens, all current intents (at that point in time) are collated together at the element level, and then all processing from that point on is done in real-time.
The proposed solution involves adding the ability to perform this processing ahead of time, rather than in real-time. Currently, there is no way to do this: any intents that are given to the engine are for immediate execution. We would need to add interfaces/calls to be able to request the engine process a given set of intents for their elements, and return the data in a more processed form. This will give us the ability to perform a large chunk of that CPU intensive work ahead of time.
Conversely, we would need the ability to feed this data back to the engine somehow, at an appropriate point (ie. where the pre-processing stopped).
Given the flow of the engine, and where the intensive work sections lie, the most obvious candidate would be to render to and save the Command values that are used by the controllers. The operation of the controllers also lends a suitable point to insert this data at a later point: at the command combination stage.
Thus, with pre-processed data, the data flow would look like this:
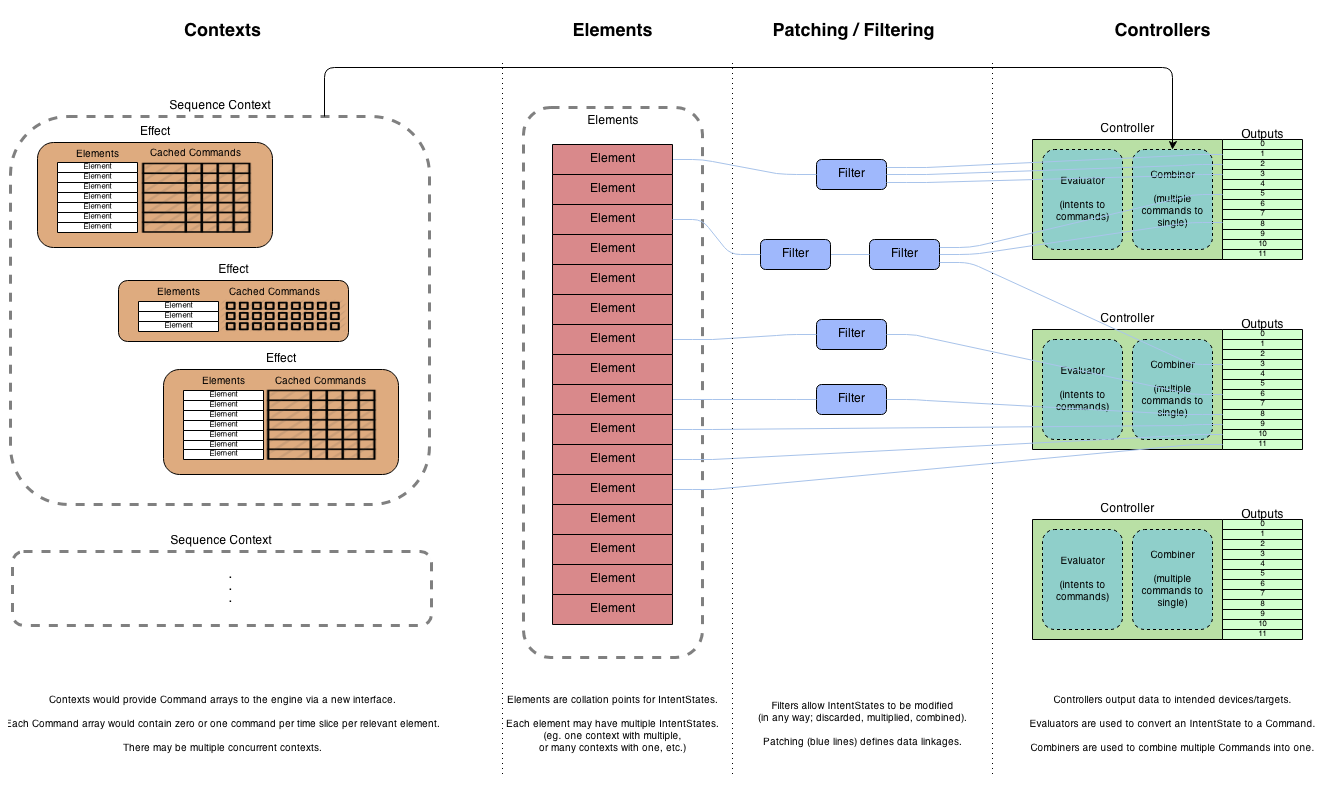
The line at the top indicates the contexts providing rendered Command data directly to the controllers via a new interface.
Other Solution Notes
These are some other miscellaneous notes/considerations about how it would work or be implemented.
Timing information
The pre-rendering results/data that the engine provides would be an array of Command values. As there is no timing information inherent in these values, the wrapper data structure would also contain the information needed — eg. if the data is in 25ms chunks, 50ms, etc. This information will be needed by whatever is retrieving the data; ie. to index into the array accurately to get the correct Command value.
Intents: not needed anymore
In the old process, effects had to store their generated Intent values, as they were the data that was used to give to the engine. In the new process, they would still be needed (to provide to the engine to pre-process and generate cached data), but only as transient data: they would be able to be disposed of afterwards. This can be of great benefit for some cases where we have many small effects with many small intents: we would only be keeping the data that is needed and used at the end.
If we were to discard intents after their brief existence, we need to consider if we need them around for anything else. Currently, they are also used for two other things that I know of: generating the bitmap of the effect in the sequencer, and when providing data to the preview modules at runtime. This needs more thought, to ensure we can work around both of these, but a quick consideration makes it seem possible:
- The bitmap can still be generated from the intents if that’s the best option: we would need to make sure that it is generated during the transient time that we have the intent data. After that, the bitmap can be cached.
- The preview module type integration into the system has never been ideal. It may be worth reconsidering how they get data in the process, and where they lie. (If we implement smart controllers, maybe they would be more suitable there? Or, maybe we can come up with a different cache format for the previews that would be suitable for them.)
Are there any other places that we use intent data that anyone can think of?
Tracking Changes
If we cache data for later execution by pre-processing information against a specific configuration, we need to make sure we know if that configuration changes (or the source information). As such, we need to be able to know if/when we should discard the pre-processed data.
I thought there was a ticket covering this work, but I can’t find it. Essentially, I had plans to add a new extension that could be applied to objects that give them the ability to track their state instances, by keeping a random ID. This ID would be changed every time the object changes in any sort of significant way. Other items that use the object would track that ID, and if if’s not the same as the current one, they know that their data is out-of-date.
For example, the system config could have an instance ID, which changes every time the configuration is changed. The effect caches would be rendered against a specific instance of the configuration, and track that instance ID. They would also track the instance ID of the effect that they are caching. At any point they are able to detect if the effect or display configuration changes, and if so, we know the cache is invalid and needs to be regenerated.
Memory vs. Disk Storage
This solution should hopefully reduce the amount of memory used, as it eliminates the need to keep Intent and IntentState objects, and only saves the raw data being used by controllers. We can save the amount of active memory used even further, though, by saving some of it to disk as needed.
In some cases, eg. working in a sequence in the editor, we would likely want more cached data available, so can keep it in memory. In other cases, running a show through the scheduler we wouldn’t want to keep ALL cached data in memory for all sequences. When not playing a particular sequence, we could save the cache for its effects to disk, and read it in later as needed.
There’s more detail we could go into here, but that’s a general idea.
TODO: disk cache could be generalized a bit, and also used for bitmap image caching
Persistence of data between software sessions
TODO: saving all cache to disk to persist
TODO: file naming/location/format/serialization
Maintaining real-time intent execution
What do we lose?
TODO: (only really the ability to dynamically process intent states in the filtering stage. However, our current filters are static, and we don’t [yet] have any filters that are dynamic in this step.)_
Solution Assessment
So, how does all this solve the initial problems?
CPU Load Concerns
It should be fairly straightforward how this addresses CPU load: the most intensive parts when rendering it real-time are all the parts in the middle of the diagram. (interpolating intent states, processing through filters, evaluating IntentStates, etc.). Not having to do this work means we save a lot of CPU time.
What CPU use do we still have? well, looking at the diagram, the following areas present themselves:
- Contexts: there would still be multiple effects in the sequence, each with their own cache of pre-processed data. There is still some CPU involved in iterating through effects, and tracking which ones are current or not. This should be fairly negligible; most sequences have a reasonable number of effects (100’s, maybe 1,000?), and these are already sorted by time order. Iterating through them in order over the course of a sequence is trivial.
- Data injection setup: as the effects with pre-cached data run, they would still need to attach to their respective controllers and/or channels to provide data. This needs a bit more careful thought, and care taken during implementation, especially with large channel counts. It should be possible to attach per controller, which would avoid too much CPU overhead.
- Data retrieval: as long as the cached data is stored in a way that allows for easy, linear iteration, ie. an array,there should be very little overhead needed to pull values out of the cache.
- Command combination: The final step is combining multiple commands. This should still be fairly easy to do, for two reasons: the actual algorithms are fairly simple to combine data, and there’s often not too much data to combine. That is, I would estimate that most of the time, there is only a single effect or intent playing for a given channel.
Memory Concerns
There are a number of ways that memory usage should be mitigated:
- Storing raw command data instead of their source intent values. This avoids a lot of transient IntentState and Intent objects. [side note: technically, it would be possible in some circumstances to *increase* memory usage, as we could be storing lots of redundant or linear command values, instead of a single intent the accurately describes it. However, the practical usage means this shouldn’t really be a problem.)
- Any cached data that is unneeded (eg. scheduler show sequences that aren’t currently playing) can be stored on disk only, and flushed from memory. This means we only hang on to what we REALLY need.
Scheduler Concerns
The scheduler problems mentioned above would mostly be mitigated by this solution: data would be cached and ready to go (persisted on disk), so the scheduler can open and start playing sequences with very little delay.
It’s also worth noting that some extra work should be done on the scheduler regardless: improvements to make it a bit smarter about getting data ready ahead of time (eg. in case a sequence HASN’T been pre-processed and cached, or if it’s dirty from a display setup change, etc.).
Alternatives
There’s a few other options for various components that have been suggested or are possible. This section attempts to look at them and address how they are different to the proposed solution above.
TODO: expand on all of these
- caching an entire sequence vs. just effects (size of null data, flexibility in use and sequencer, regenerating for any change)
- inserting data AFTER the combination: ie. locking controllers to just cached data (loses a lot of flexibility and power of V3)
- storing the whole cache on disk, and streaming from there (loses flexibility)
Feedback
Was this page helpful?
Glad to hear it!
Sorry to hear that. Please tell us how we can improve.